11강, __Question Answering__
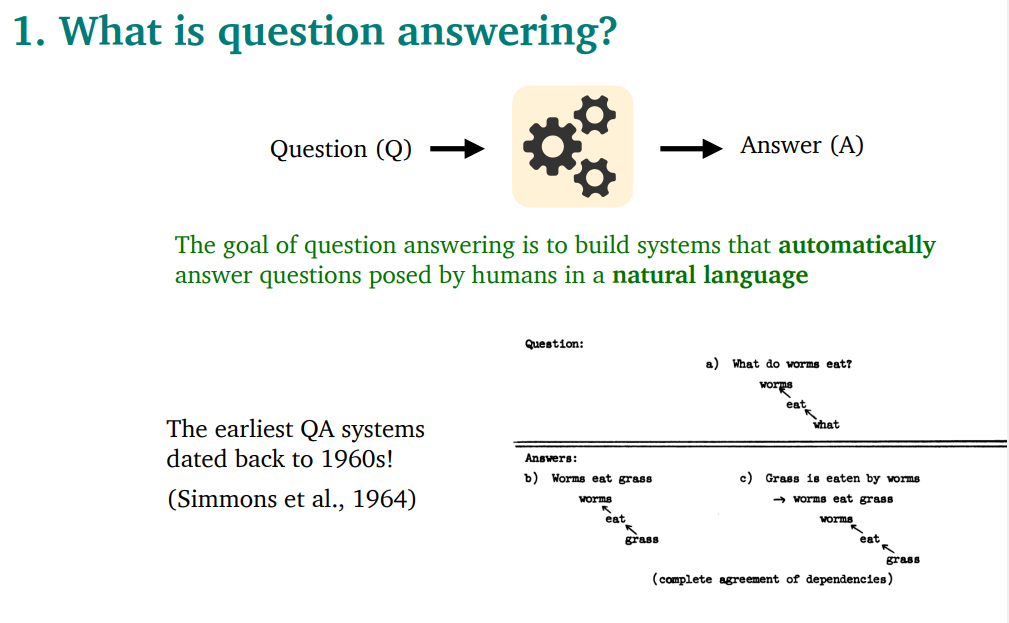
QA : 사람이 자연어로 쓴 질문에 자동으로 대답하는 시스템

QA는 정보의 출처 / 질문의 종류 / 답의 종류 등으로 분류할수 있음
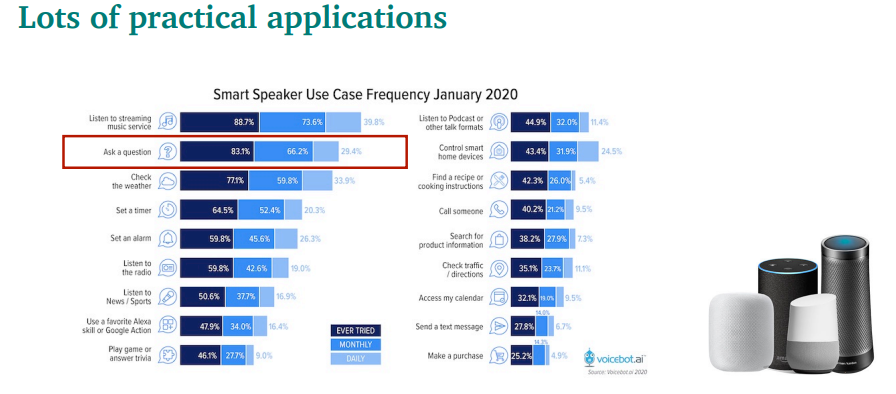
인공지능 스피커등에서, QA가 2번째로 많이 쓰이는 case임
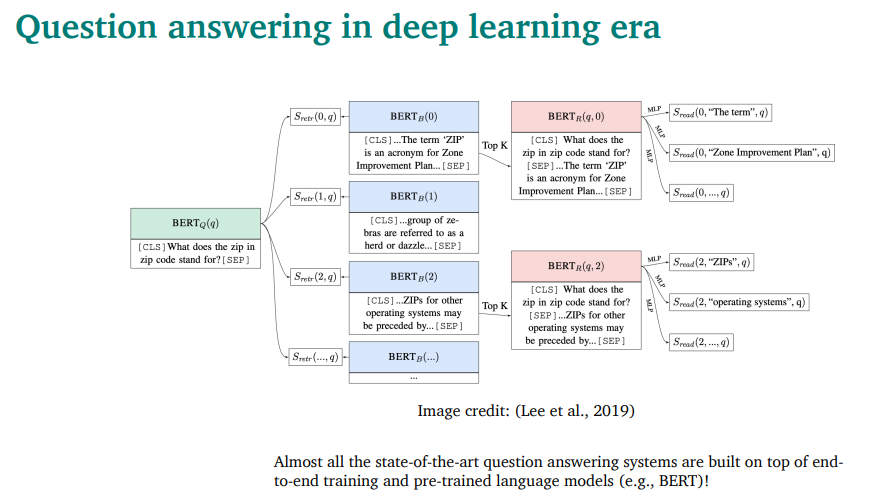
오늘날 SOTA는, pre-trained 모델을 기본으로 설계되어있음


이런 문제들처럼 text 이외에서도 QA를 할 수 있음(다루지는 않을거임)

Reading comprehension : P(passage)와 Q(question)으로 A(answer)을 구해야함.
이런 task는 인간에게는 쉽지만, 기계에게는 어려움

왜 이 task가 필요한가?
- 실제로 응용하면 유용함(앞에서 본대로)
- 컴퓨터가 사람 언어를 얼마나 잘 이해했는지에 대한 평가 척도가 됨
- 많은 NLP task들이 reading comprehension으로 reduce 가능함
- Information extraction
- semantic role labeling(동사의 주체 같은거 찾는거)

SQuAD 데이터셋 - 100K짜리.
100~150 단어의 passage, 그리고 답은 짧은 단어.
거의 solved됨.(많이 어려운 데이터셋이 아님)

2개의 eval metric - exact match / F1
3개의 중복정답이 있음. 걔네를 predicted answer랑 비교해 최대값을 취함.
Q. QA로 NER같은 시스템을 fine-tuning 할 수 있는가?
A. 무조건 그렇다고는 할 수 없다.

C=Paragraph / Q = Question
2016~2018에는 LSTM + attention 모델이 대세였음
2019이후에는, BERT(bert-like)를 fine-tuning한 모델이 대세임
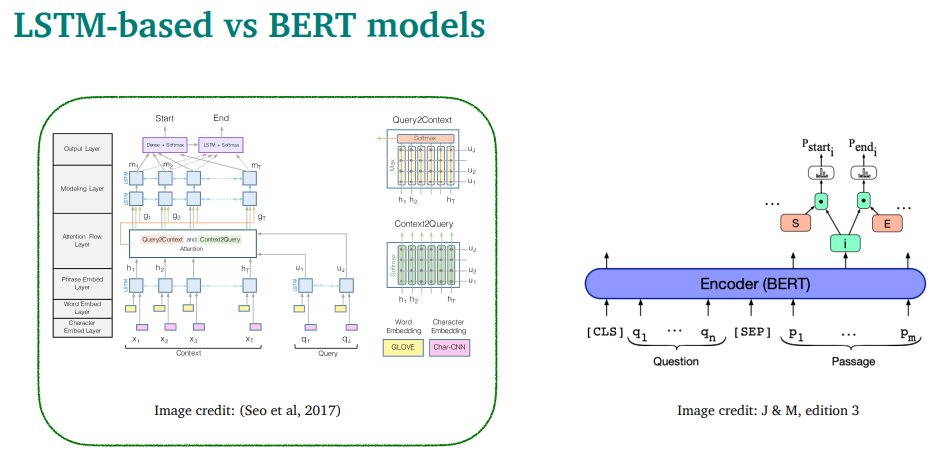
왼쪽이 LSTM + attention, 오른쪽이 fine-tuning
왼쪽에대해 일단 설명을 해보겠다
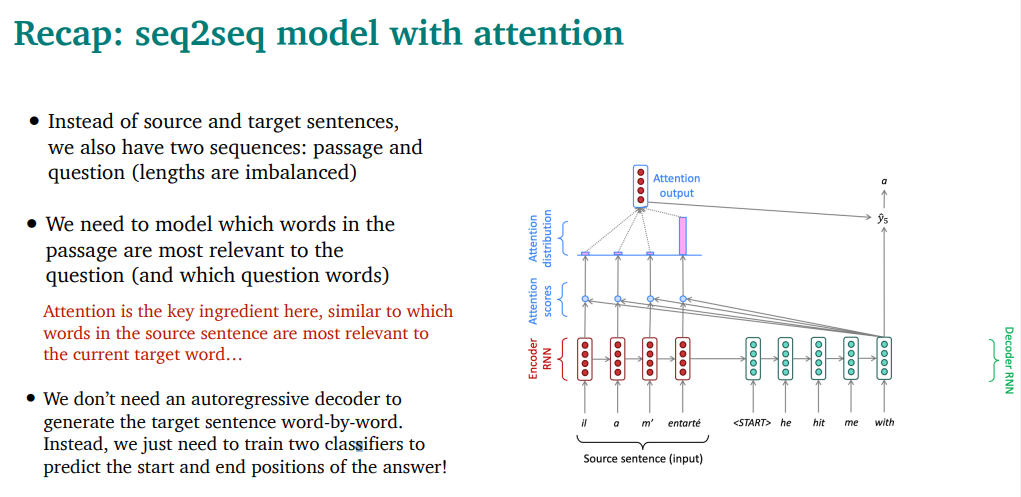
translation이랑 reading comprehension은 많이 비슷한 분야임
둘다 2개의 sequence를 가지고 있음.(source-target / passage-question)
모델은, passage에서 question에 가장 가까운 word를 찾아야됨. 이건 translation에서 target word에 뭐가 가장 가까운지 찾는거랑 비슷함 → attention이 매우 좋겠다
다른점은, reading comprehension에서는 generate안해도 됨. 그냥 start랑 end position을 구하는 classifier만 필요함
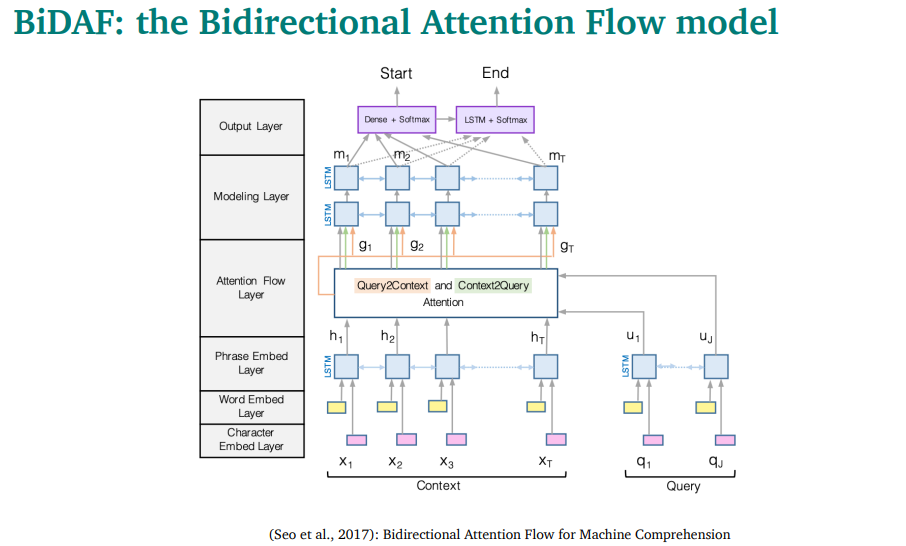
복잡해보이지만, 그냥 layer쌓은거임

Embedding 파트
word embedding(GloVe 사용)하고 character embedding을 둘다 사용해서 concat함
그리고 나서, bidirectional LSTM2개를 사용해서 contextualize embdding을 얻기 위해 C와 Q를 각각 넣음.
bidirectional쓰는 이유는, generate안해도 되니까..

Attention flow layer
attention은 context와 query간의 interaction을 파악하기 위한거임
두가지 attention을 사용함
- context to query attention
각각의 context word에서, query에서 가장 유사한 단어를 찾음
예시를 보면, 화살표대로 찾는다고 볼 수 있음
- query to context attention

query word중 하나랑 가장 비슷한 context word를 찾는거임

- context vector C와 question vector Q의 모든 pair에 대해서 simirality를 계산함. 그리고 concat해서 S vector를 구함(첫 식)
- context-to-query attention을 구함. 아까 구한 S의 softmax를 구해서 alpha를 만듬.(내생각엔, 이게 attention score랑 비슷한거일듯?) 그리고 alpha와 q를 weighted sum함.
- query-to-context attention를 구함. question word마다의 S의 최대값을 구하고, 그것의 softmax를 구하고, 똑같이 weighted sum을 하는데, 이번엔 c랑 함.
그리고 이렇게 구한 값들을

이렇게 concat하고, element곱하고 해서 만들어냄
Q. 왜 query-context랑 context-query랑 attention이 따로 있는가?(왜 not symmetrical한가)
A. 둘이 다르기 때문임. span가능성도 있고…
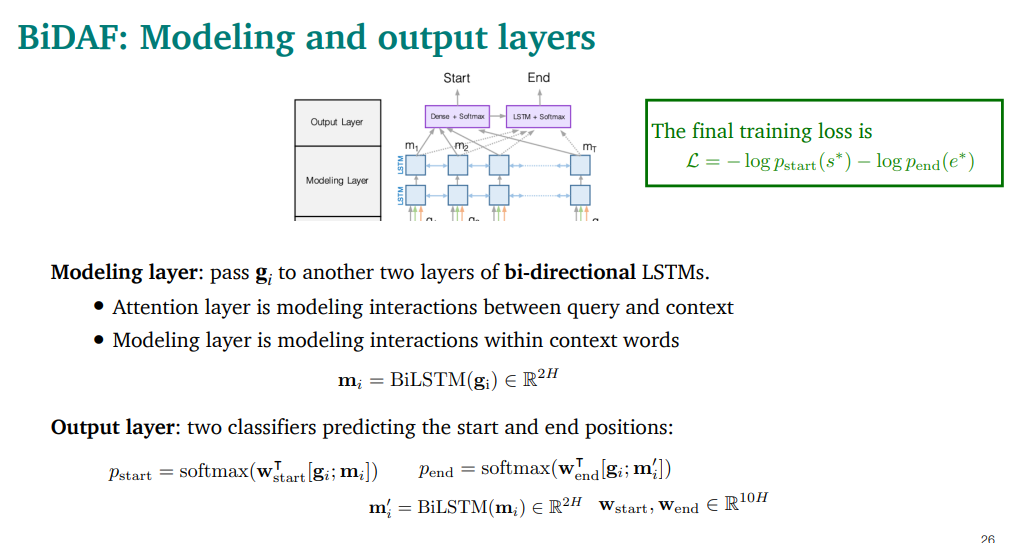
마지막 layer인 modeling and output layer
modeling layer
아까 계산한 gi 를 bi-directional LSTM에 또 태움.
context word간의 interaction을 계산한다는 측면이 큼
output layer
start/end position인지 구분하는 classifier 2개가있음

loss는 gold answer의 start와 end와의 차이를 봄.
형태는 그냥 negative log loss임

성능은 이랬음. attention 양쪽중에 하나만 없어져도 score가 떨어지는걸 볼 수 있음.
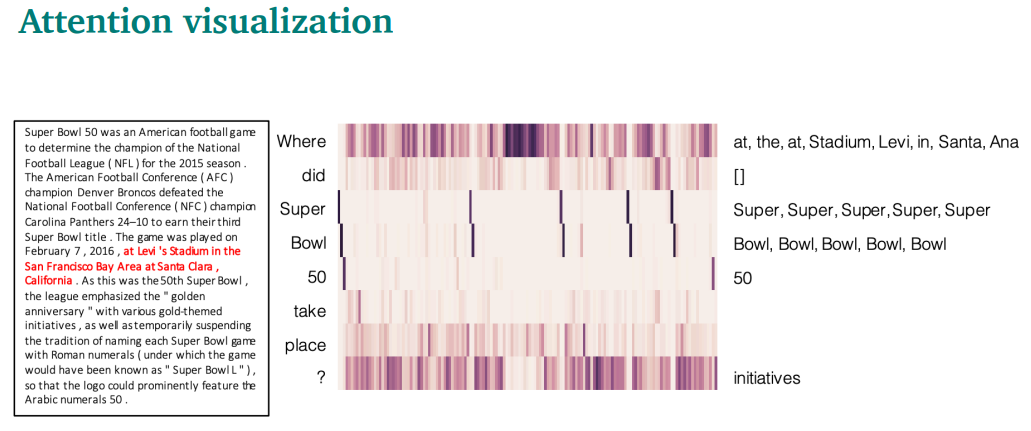
attention score를 visualize할 수 있는데, where 이 stadium 등에 attention을 높게 준걸 볼 수 있음
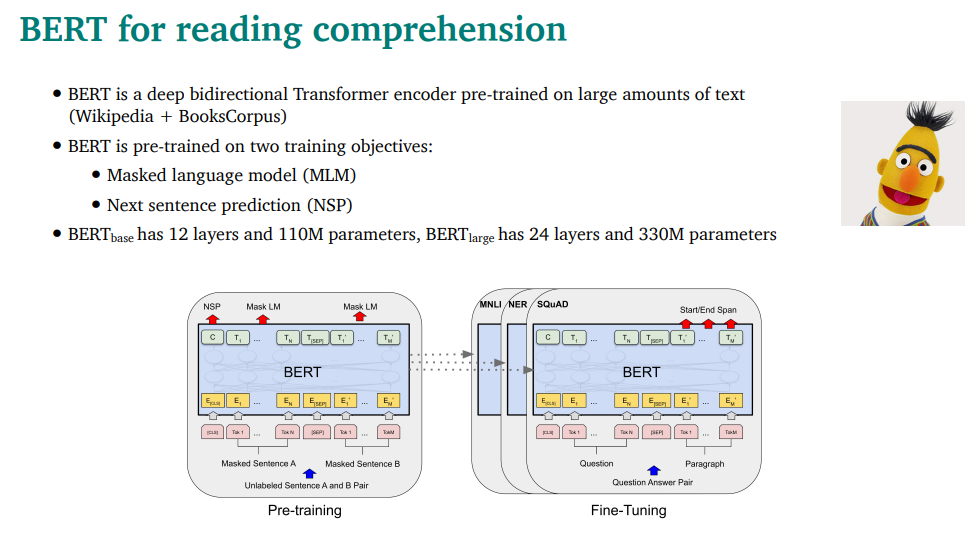
BERT을 reading comprehension에 쓸 수 있음
복습을 잠깐 하면, MLM과 NSP로 pretrain하는 모델
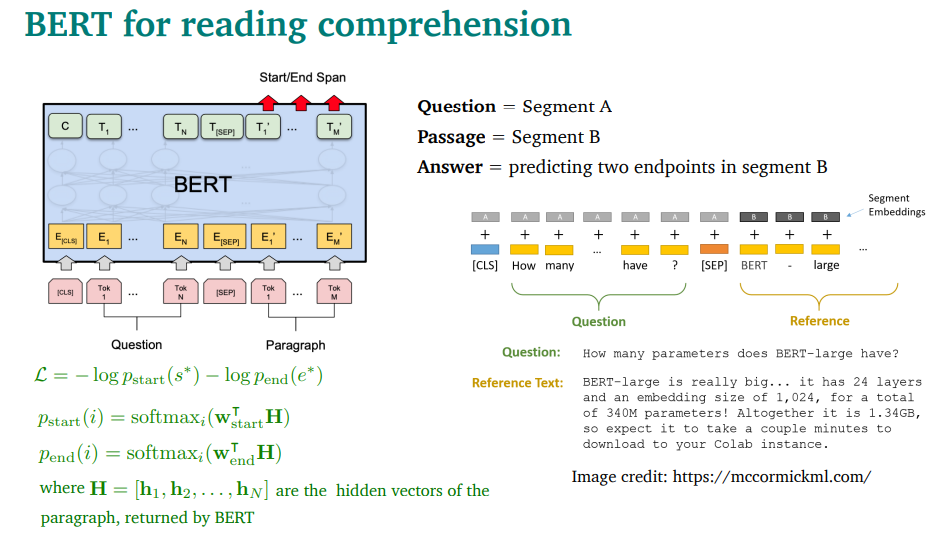
Question을 A, Passage(reference)를 B로 넣고, Next Sentence Predinction을 하는거임
bert encoder의 출력인 hi를 W와 곱해서 softmax를 취해서 start,end를 구함

BERT 모델에 start랑 end 구분에 쓸 파라미터 추가
매우 잘 동작함. SQuAD가 pretrain model을 테스트하는데 보편적으로 쓰이게 되기도 했음

BiDAF와 BERT를 비교해보자
BERT는 파라미터가 매우 많고(110M) BiDAF는 2.5M밖에 안됨
BiDAF- LSTM / BERT - transformers
BERT는 pretrain됨. (pretrain이 최고다…)

둘이 근본적으로 다른가? 아마 그렇지는 않다(발표자 주장) passage와 question사이의 attention이라는 접근 방식은 비슷함.

pretrain 방식을 바꾸면 더 낫나?
SpanBERT같이 masking방식을 바꾸거나 할 수 있음.

spanbert성능이 더 좋다.
model 구조를 바꾸거나 데이터셋을 늘리지 않고 pretrain방법만 바꿔도 더 나은 결과를 얻을 수도 있다.

reading comprehension은 solved되었나? → 아님
특히 out-of-domain에 약함
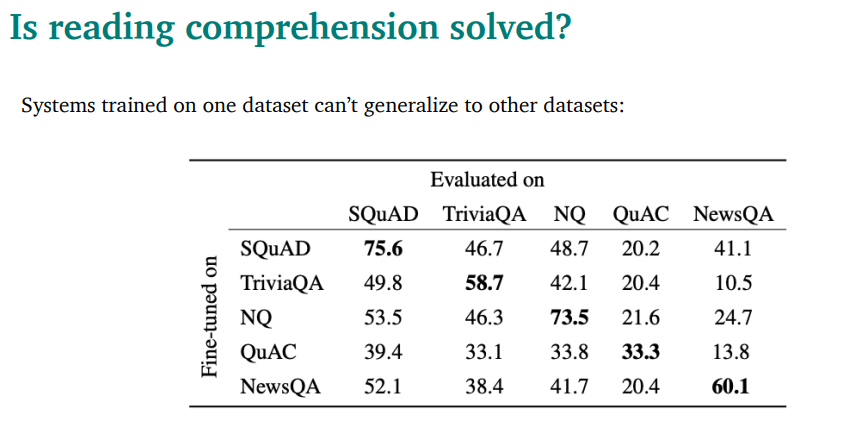
다른 데이터셋으로 가면 완전 취약해지는걸 볼 수 있음


테이블 보면 되게 간단한 문제들임. 근데 잘 대답을 못 하는걸 볼 수 있음.

Open-domain QA는 passage가 주어지지 않고, 많은 document(wiki같은)게 주어진다음에 answer을 구하게 하는것

retrieve-read 방식으로 해결할 수 있음

D = documents / Q= Question / A=answer
Retriver가 question과 관련된 K개의 Passage P를 추리고,
Reader가 P들을 보고 Answer을 구하는 구조
2017년논문이라 구조가 매우 단순함
Retriver는 TF-IDF를 썻고,
Reader는 그냥 neural reading comprehinsion을 씀(SQuAD등으로 학습함)
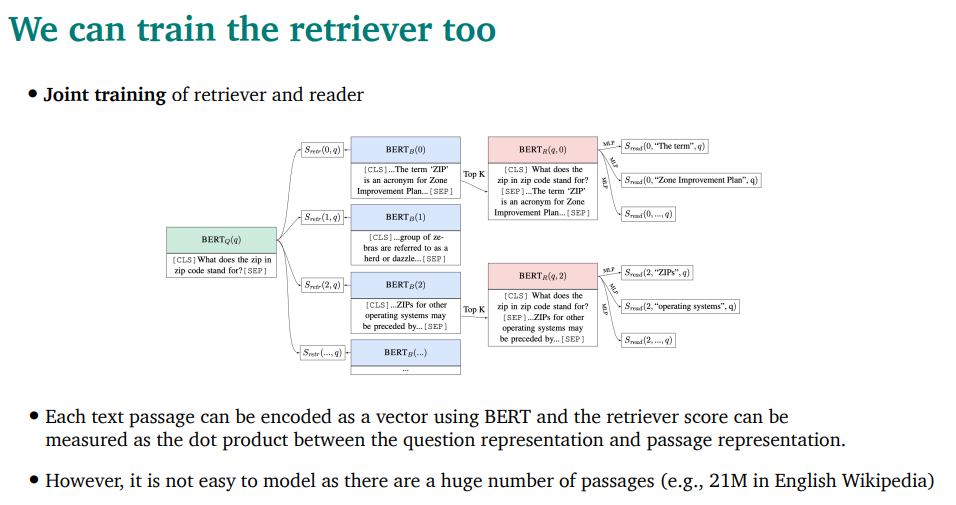
최근 아이디어들로
Retriver와 Reader를 같이 training할 수 있음. 그렇지만 쉬운일이 아님…
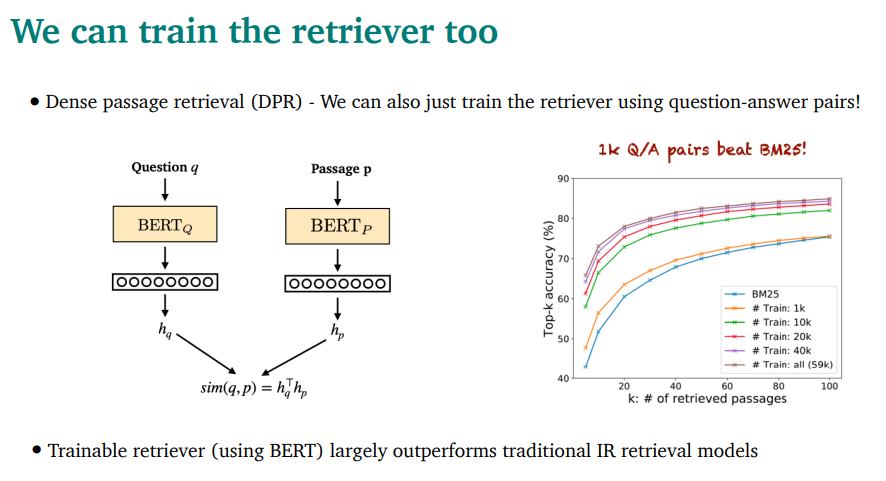
DPR(Dense passage Retrieval) - retriever를 그냥 QA pair를 이용해 학습함
두개의 BERT를 각각 사용해서 뭐 어케어케 했음
성능 매우 좋았음
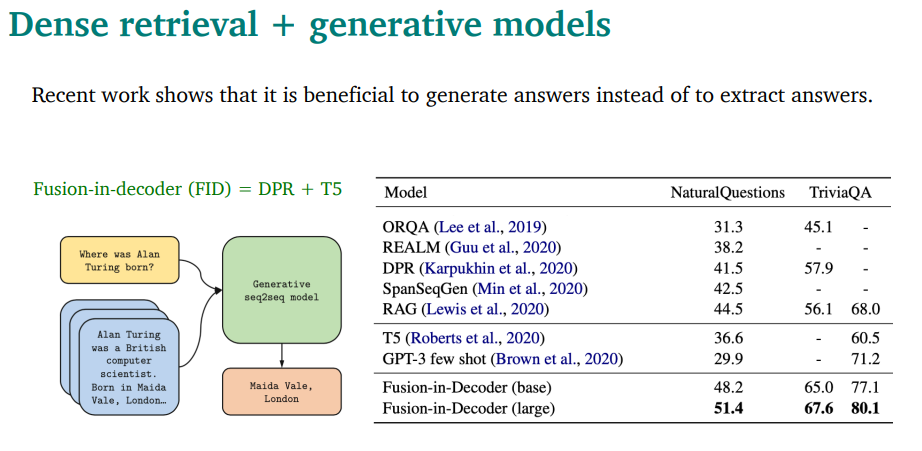
지금은 이런 dense retrival + generative model이 지배적임
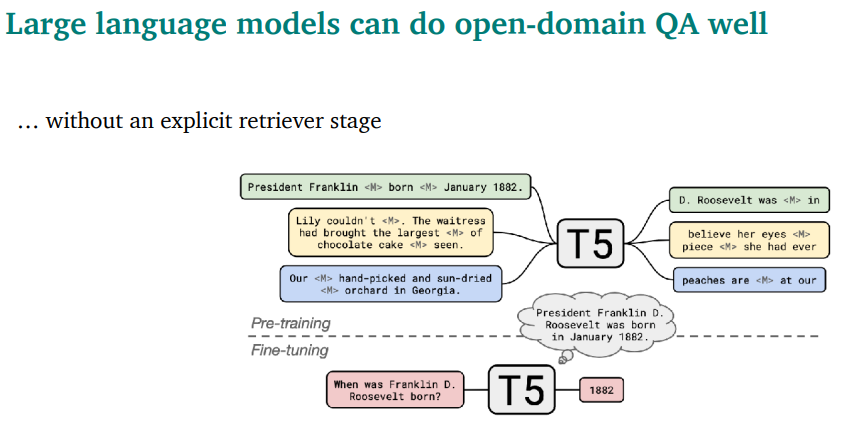
만약 엄청 큰 모델을 써버리면, retieve가 필요 없을수도 있음…
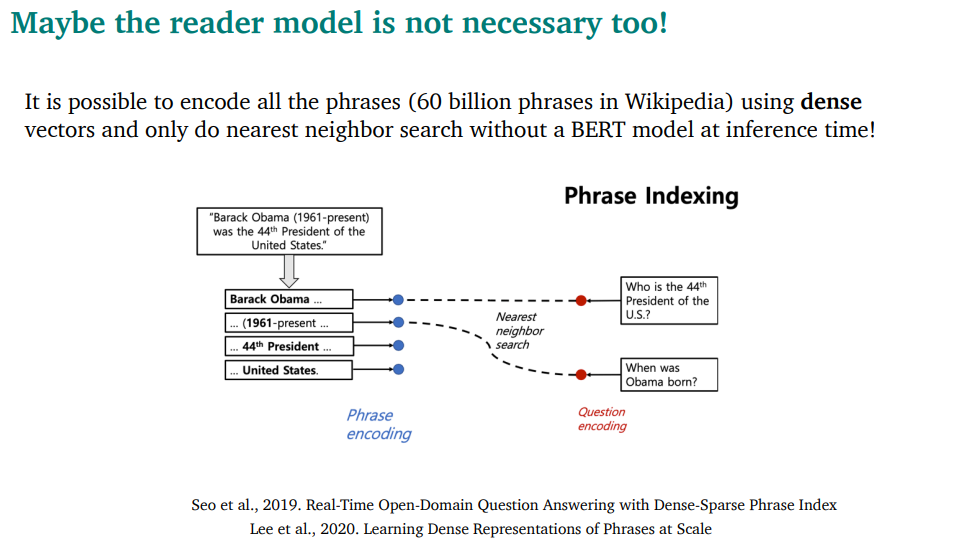
reader 모델도 필요없을 수도 있음!!
그냥 dense vector를 저장하고, nearest neighbor search를 해버릴 수도 있음
BERT모델 돌리지 않아도 되어서 매우 빠르고, CPU로도 할 수 있을정도임
Uploaded by N2T