문장에서 이름을 가진 개체를 인식하는 것. 이름, 장소, 시간같이 고유명사같은 것들을 다른 일반 명사와 구분해서 인식하는 것.
NER 전통적인 접근법
Rule Based : 사전(gazetteer)을 적용함. 다른 도메인으로가면 정확도 낮아짐
Unsupervised Learning : 문맥적 유사도 따라서 분류함. 문법적 지식에 의존함
IOB 표현법
B = Begin, I=Inside, O=Outside. 각각 개체명의 시작, 중간(끝포함), 개체명 아님을 나타낸다.
예를들어, ”해리포터 보러가자” 라는 문장이 있으면, 해=B, 리,포,터=I, 보,러,가,자=O
Abstract
당시 SOTA NER모델은 도메인 의존 지식(gazetteer)이나 수제작한 features에 의존함
우리는 biLSTM과 CRF, transition-base방식의 접근으로 진행했다
word-representation은 supervied charactor-based랑 unannotated corpora에서 학습한 unsupervised 것 두개 사용함
CRF
IOB 표현법 특징은, 등장하는 순서가 있다는 것이다. 예를 들어, I-PER은 B-LOC뒤에 나올수 없고, B-PER뒤에는 I-PER이 나올 확률이 높다.
그래서 각 문장 X에 대해서 다음과같이 나누면,
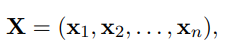
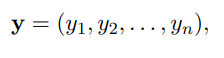
이때 x1,y1은 각각 문장의 한 단어와 그 단어의 예측값이다.
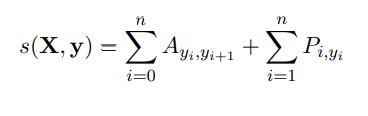
그래서 score를 이렇게 나타낸다.
Aij는 tag i에서 j로 transition할 확률이다.(B-PER에서 I-PER로 갈 확률)
Pij는 i번째 단어(xi)에서 j번째 태그(I-PER인지, B-PER인지)의 score이다.
y0, yn은 start랑 end 를 tag로 써서, 행렬 크기가 k+2가 된다(k=tag의 개수)
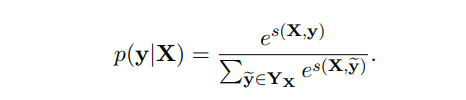
가능한 모든 태그 순서에 대해 softmax하면, y을 어떻게 배치할지 순서가 나오고(Yx는 가능한 모든 순서의 집합)
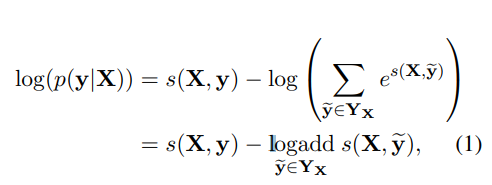
학습할 때에는, 맞는 순서에 대해 log-probability를 최대화하는 방식을 사용한다.
모델 구조
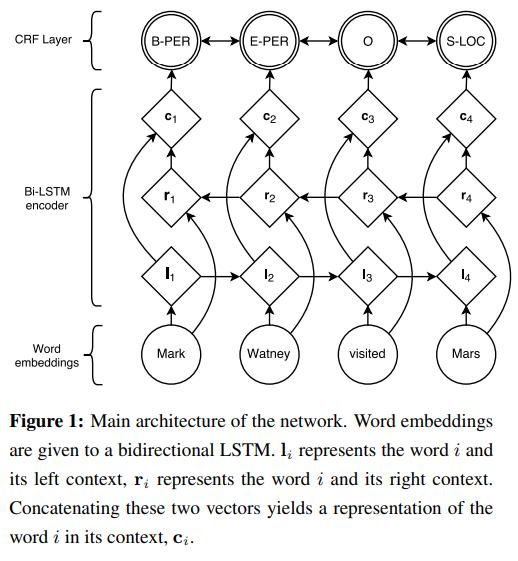
BiLSTM을 사용하면 li와 ri의 두개의 context가 나오는데, 이를 concat해서 ci라는 벡터를 만들어서, CRF의 입력으로 사용한다.
다른 시도들
- IOBES라는 태깅 시스템을 써봤는데(E=End, S=Singleton) IOB보다 뭐 나아지진 않았음
- Stack-LSTMMark Watney라는 이름을 따로 인식하는게 아니라, 하나의 표현으로 인식함. 이 모델의 장점은 태그 지정체계(IOB같은)에 구애받지 않는다. 왜냐면 청크를 직접 예측하기 때문임.

- Shift-Reduce방식에서 착안(https://whoishoo.tistory.com/157)
Word Embedding
앞서 말했듯이, 두 가지 방법을 사용함
1. Character기반
이름인 단어의 특징이 단어의 스펠링에서 나타난다고 생각했기 때문에 사용함
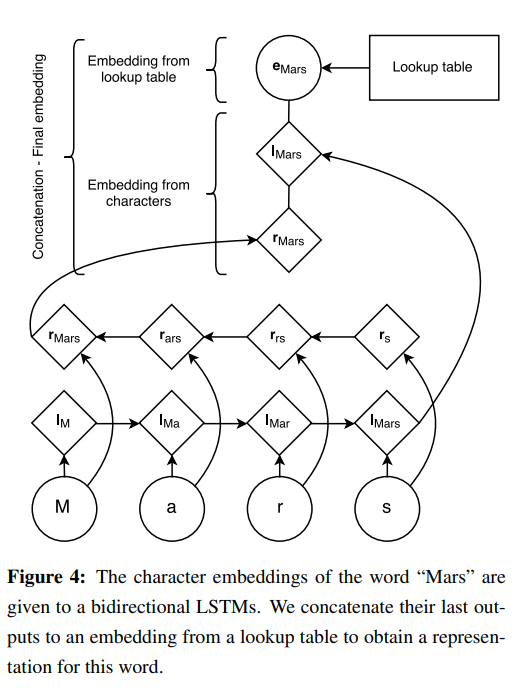
위와같이 스펠링 단위로 LSTM에 넣어서, 그 결과값을 concat해서 임베딩 벡터 만듬
2. Pretrained embedding
큰 corpora에서는 꽤 자주 이름이 등장할 것이기 때문에 사용했음
실제로, 랜덤하게 초기화하는 것보다 확연한 성능 향상
skip-gram하고 word2vec 사용했음