
어떤 모델이 좋은걸까? → 예측 결과 정확도가 높은게 좋다.
그렇지만, Accuracy만이 전부는 아니다.
- 명확한 정의가 없기도 하고
- Precison/Recall에 대해서도 고려해야하고
- 데이터셋의 validity도 고려해야 한다.

dataset이 바뀌면 잘 안 될 수도 있음. 도메인이 바뀌거나, 수집한 데이터의 variance가 충분하지 않은 경우에서 그럼.
그래서, dataset에서 일부를 test set으로 둬서 미래에 올 데이터라 상정하고 테스트함
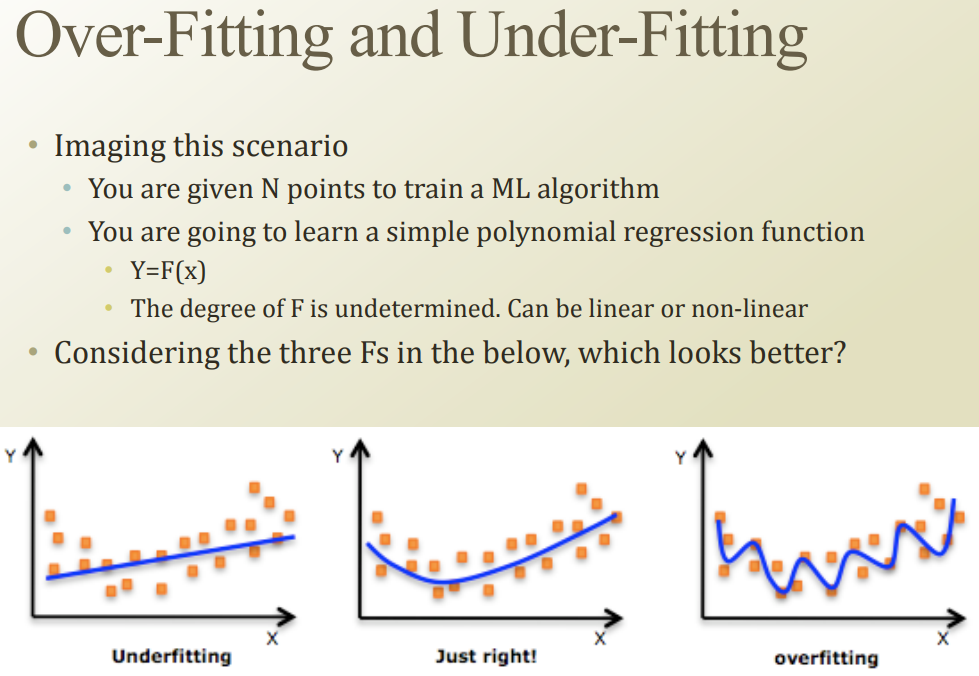
이렇게 세 함수 Y=F(x)가 있을 때, underfitting하고 overfitting을 피해야 함
모델이 너무 복잡한것도 별로다(overfitting)

머신러닝에서 에러는, approximation(예측못함)과 generalization(미래 데이터셋 오차)가 있다. 두 에러를 합한것 이하(Eout)이 우리의 에러다.
- f : true function
- g : 머신러닝 모델
- g(D) : 데이터셋 D로 학습된 모델 g
- D : 데이터셋
- g-hat : 데이터셋 D를 무한히 학습해서 만든 g의 평균

EDg(D)(x)를 하는 과정이, ghat의 avarage hypothesis를 구하는 과정과 동일하므로, 0으로 만들 수 있다.

앞에서 구한 두 식을, variance(x)와 bias(x)로 나눠볼 수 있다
- variance : 현재 데이터셋과 미래 데이터셋간의 차이때문에 생기는 에러
- bias : 모델의 한계때문에 생길수있는 에러(ghat과 true function간의 차이)
둘 간에는 trade-off관계가 성립한다.
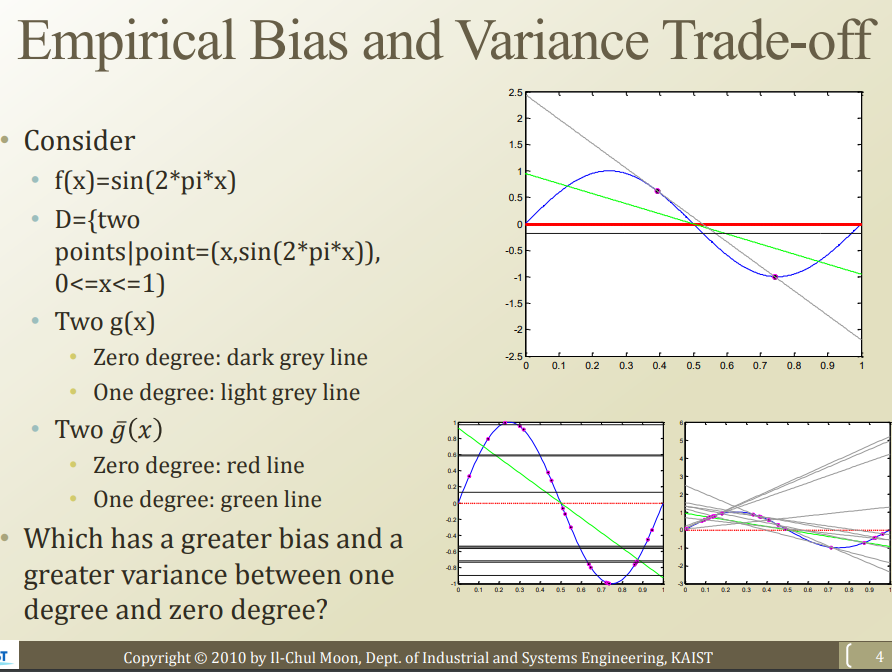
sin 함수를 true function이라고 가정해보자

왼쪽 y=0 상수함수는 bias가 높고, 오른쪽 일차함수는 variance가 높다.
→ complex한 모델은 var높고 bias낮고, 간단한 모델은 var낮고 bias 높다.
여러개의 hypothesis가 있을때, 심플한게 낫다.(Occam’s razor)

사실, 무한하게 sampling을 할 수 없기 때문에, g-hat같은건 불가능함. 그래서 대충 n번쯤 해보는거야. 그게 N-fold cross validation.
가진 데이터를 N개로 자르고, 각각의 subset중 N-1개를 train, 1개를 test에 쓴다. 그걸 N번 반복하고, 이 N이 늘어나면 infinity sampling과 유사해질 수 있음
근데, 그걸 하나의 instance만 test로 쓰고 나머질 다 train에 쓰면 LOOCV(Leave One Out Cross Validation)

사실, Bias와 Variance는 현실에서 구하기 힘들다.(True func 모르고 infinite sampling도 안됨)
대신, Accuracy, Precision & Recall이라는 방법을 사용함.
Precision은 정확성. False-Positive를 줄이는 방식(스팸필터)
Recall은 재현성. False-Negative를 줄이는 방식(VIP 찾기)

F-Measure는 Precision&Recall을 가중치를 적당히 주면서 쓰는것(F1은 몇번 본거같음)
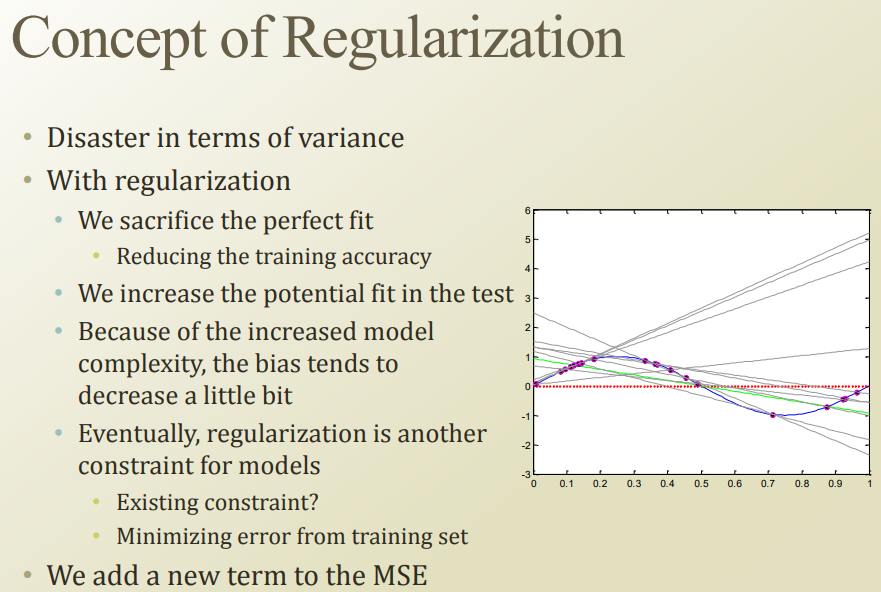
현재 데이터만 가지고 모델 만들면, variance때문에 큰일날 수 있음
Regularization : test set정확성 높이기 위해서 perfect fit을 포기하는 것. (너무 데이터셋에 민감하게 반응하지 않게 하는 것)
overfit막는방법으로 모델 complexity 낮추기도 하지만, regularization이라는 방법도 있음

오른쪽 밑을 보면, 어떤 constant term을 붙여서, 어떤 특정값(w)가 너무 커져서 에러가 줄어드는 것을 방지하고 있다.
term의 모양에 따라 Lasso, Ridge, Bridge등이 있다.
Ridge(L2 Regularization)을 가장 많이 사용한다.


w값을 조절해서 전체를 optimization하는거니까 w에 대해서 미분해본다.
그러면 오른쪽아래 식의 gamma I 식이 추가된걸 볼 수 있음
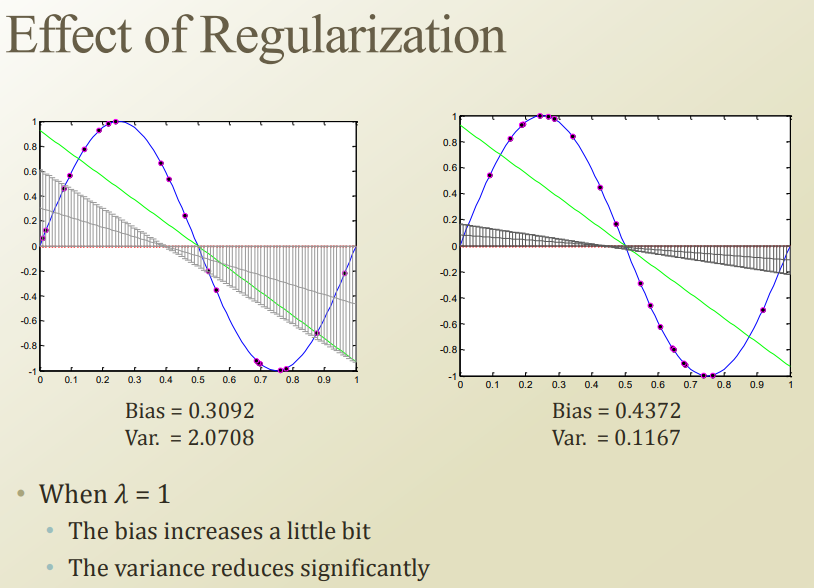
regularization해보니까 bias는 조금 늘었지만, variance가 많이 줄은걸 볼 수 있음

람다가 작으면 variance가 너무 커지고, 람다가 커지면 variance가 작아지게됨.


Logistic Regression, SVM에서도 Regularization할 수 있음. logi에서는 closed form이 아니라서 좀 힘들거고, svm에서는 이미 C가 gamma와 유사한 기능을 하고 있음
Uploaded by
N2T