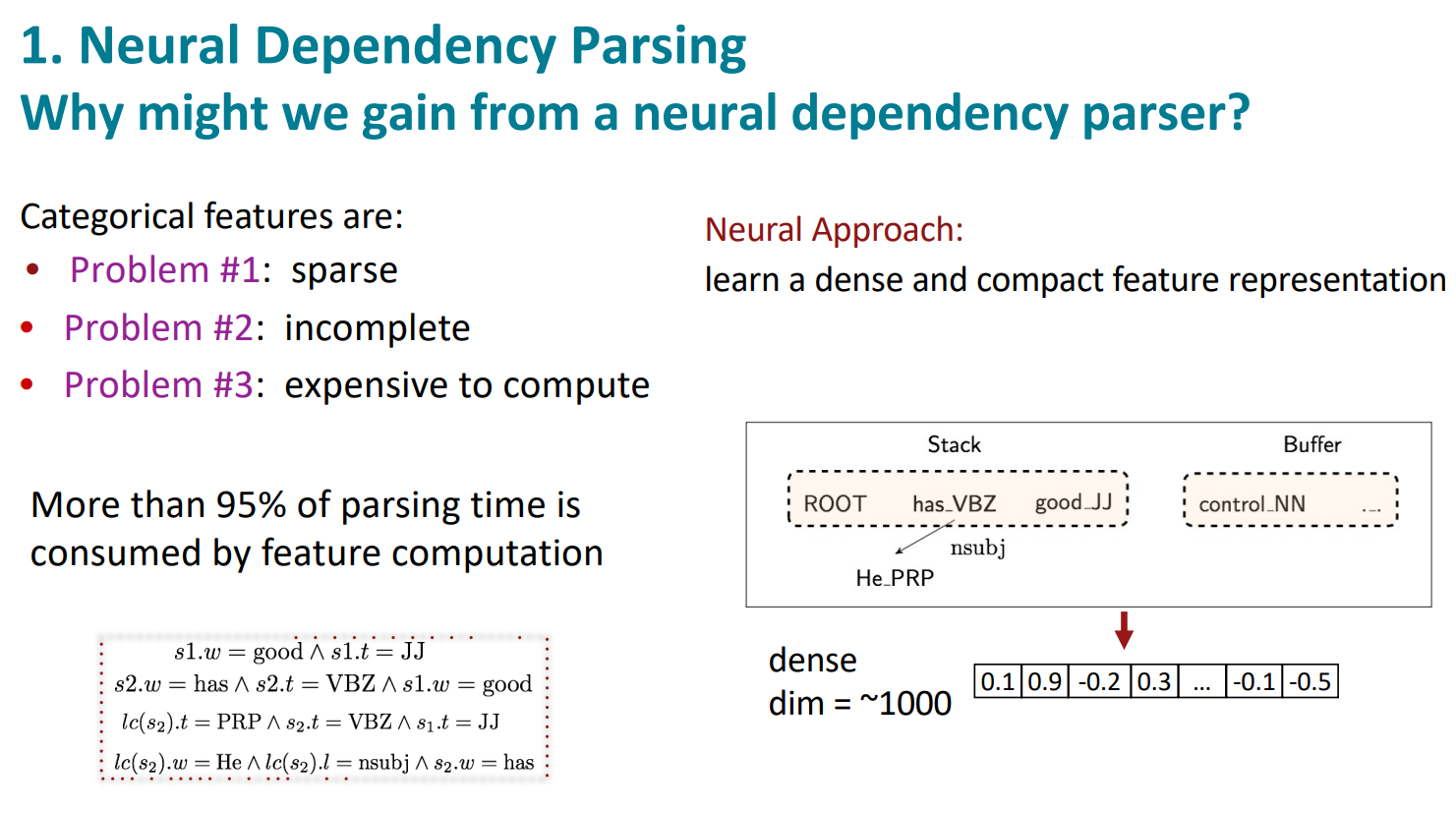
categorical features에는 문제가 있음
- sparse(희박)하고
- 완전하지 않고
- 계산하기 너무 비용이 많이 든다
그래서 Neural Approach를 한다. 나머지(stack, buffer…)는 똑같지만 더 dense한 벡터를 학습함
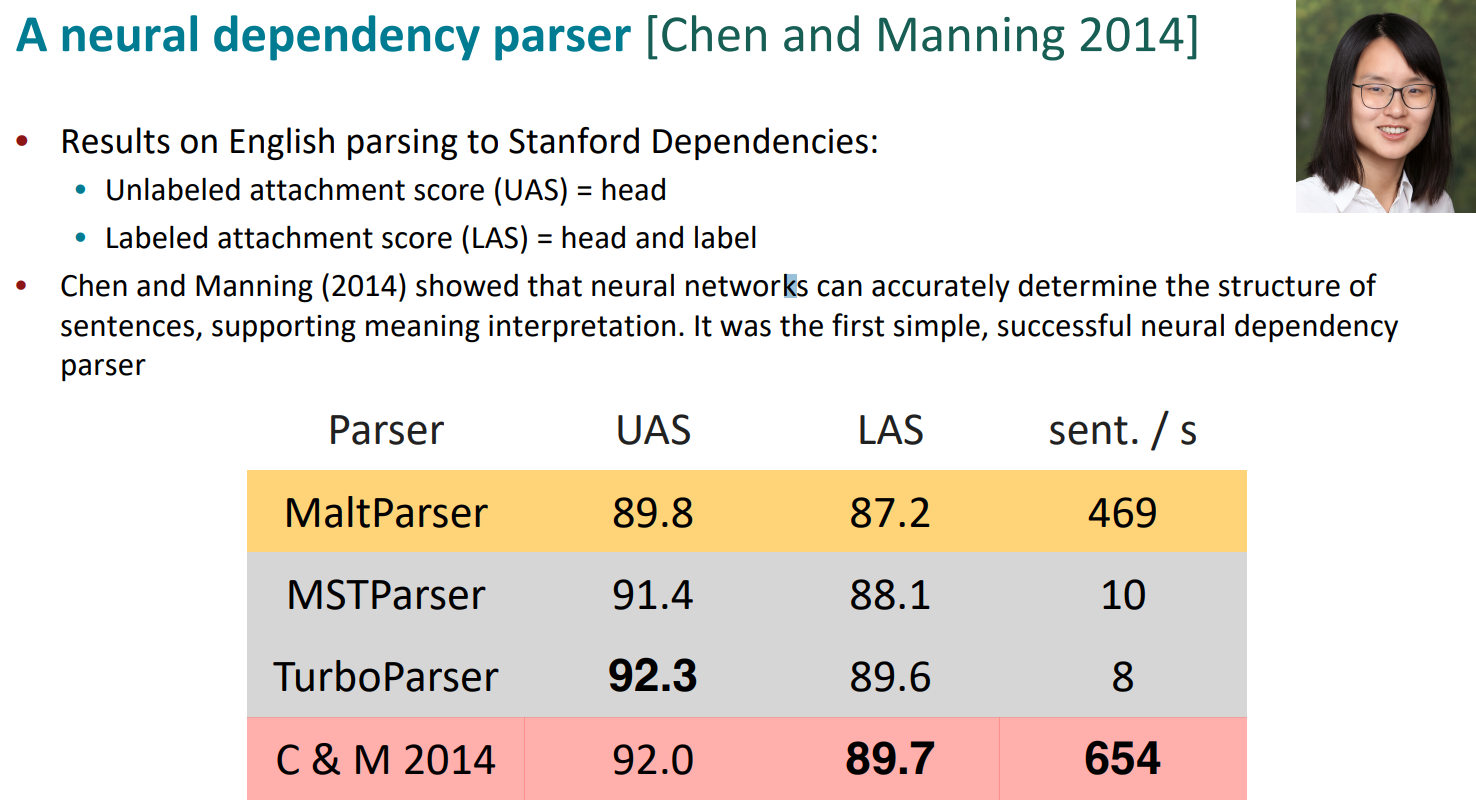
Neural dependency parser는 symbolic dependency parser보다 훨씬 빠름

성공한 첫번째 이유는 Distributed Representations(=Word embedding)을 사용했고, part-of-speech tag(POS)와 dependecny label도 vector로 표현했음

stack/buffer 에서 word, POS, dep.의 벡터를 추출해 이를 concat해서 사용함

두번째 이유는, DL classifier가 non-linear하기 때문이다. 전통적인 ML classifier(나이브 베이즈, SVM, logi regression, softmax)는 decision boundary가 선형이었다.

NN은 non-linear한 decision boundary가 가능하다. softmax는 여전히 선형 모델이지만, NN의 마지막 층에 자주 붙어있다.

dense representation → hidden layaer(non-linear) → softmax 순으로 layer를 거치는 간단한 classifier 모델이다. 언어모델에는 input layer 전에 주로 one-hot을 dense하게 바꿔주는 layer가 하나 더 있다.
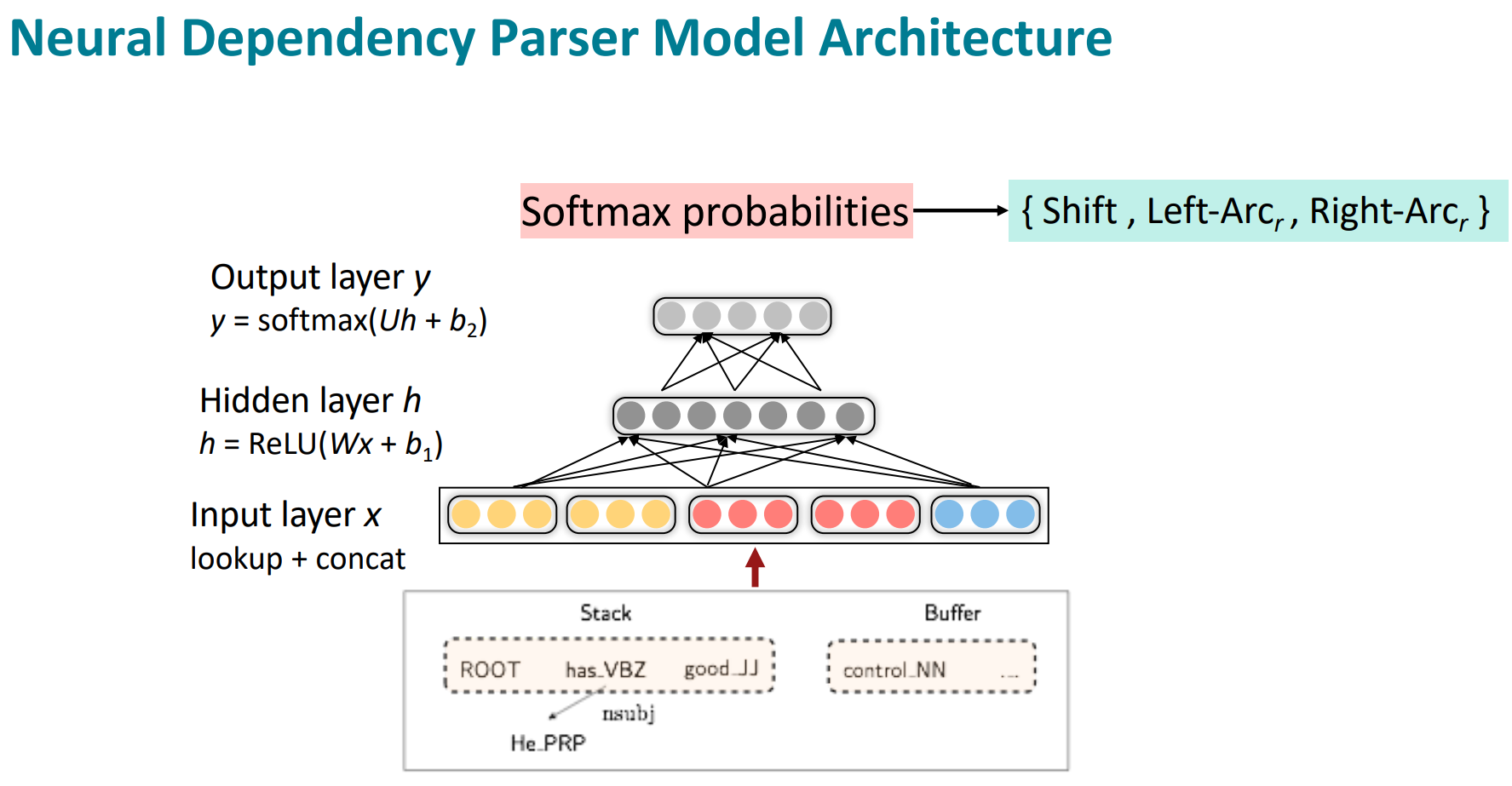
그래서 이게 Neural dependency parser 모델 구조임

이게 간단해보이지만, 최초이자 성공정인 neural dependency parser였음. 더 빨랐고, 더 정확했음

그 이후, 구글에서 더 큰네트워크, beam search, CRF등을 사용해 더 나은 모델을 만들기도 했음

transition-based parser의 대안이 grapch-based parser임. 각 단어의 모든 가능한 dependency를 계산하는건데, context를 알아야하는 문제임. 위 그림에선 cat이 가장 big의 dependent일 가능성이 높음

n^2 시간 걸리지만, 더 나은 parser를 만들었다

보통, Regularize된 loss function을 많이 사용함. regularization term은 overfitting 막기 위해서 사용됨. (참고 : https://imchangrok.tistory.com/31)
요즘에 큰 NN은 train-data에 대해 과적합되게 학습한다고함.

train할 떄, 각 instance의 50%의 입력을 0로 만들어버리는거.
이게 feature-coadaptaion(유용한거만 학습되는거)를 막아줌.
요즘은 feature-dependent rgularizer(각 feature를 다른 가중치로 정규화)로 사용함

for 루프가 아니라 vector랑 matrices를 쓰세요 더 빨라요

선형 레이어를 여러개 써도 그냥 하나랑 그다지 다른게 없음. 그래서 비선형 레이어가 있어야함. 왼쪽에서 오른쪽으로 옛날에서 최근.
sigmoid는 모두 양수(>0)으로 보내는게 문제였음.
sigmoid에서 tanh의 변화는 사실 그냥 조금 scaled, shifted 된거 뿐이었음. 그리고 이런 초월함수는 계산하기 좀 어려움
그래서 hard tanh → ReLU(요즘 가장많이씀)으로 넘어옴
ReLU가 좋은점은, train이 빠르게되는것임
Leaky ReLU, Swish등도 있다

NN을 0으로 시작하면, symmetric하기 때문에 학습이 안됨. random으로 초기화해야함. bias는 0으로 시작해도 괜찮음.
Pytorch에서는 Xavier 초기화가 주로 사용됨. fan-in, fan-out으로 variance를 조절하는 방법임. 그냥 표준정규분포로 초기화하면 출력값이 동일해지는 문제가 생겨서 이렇게 주로 함

adam이 주로 쓰기 괜찮음.

낮으면 학습이 안되고, 높으면 발산함.
epoch마다 LR을 절반으로 줄이는게 일반적임
Adam같은 optimzer는 LR을 점점 줄여감. 그래서 조금 크게 시작하는게 괜찮을 수 있음
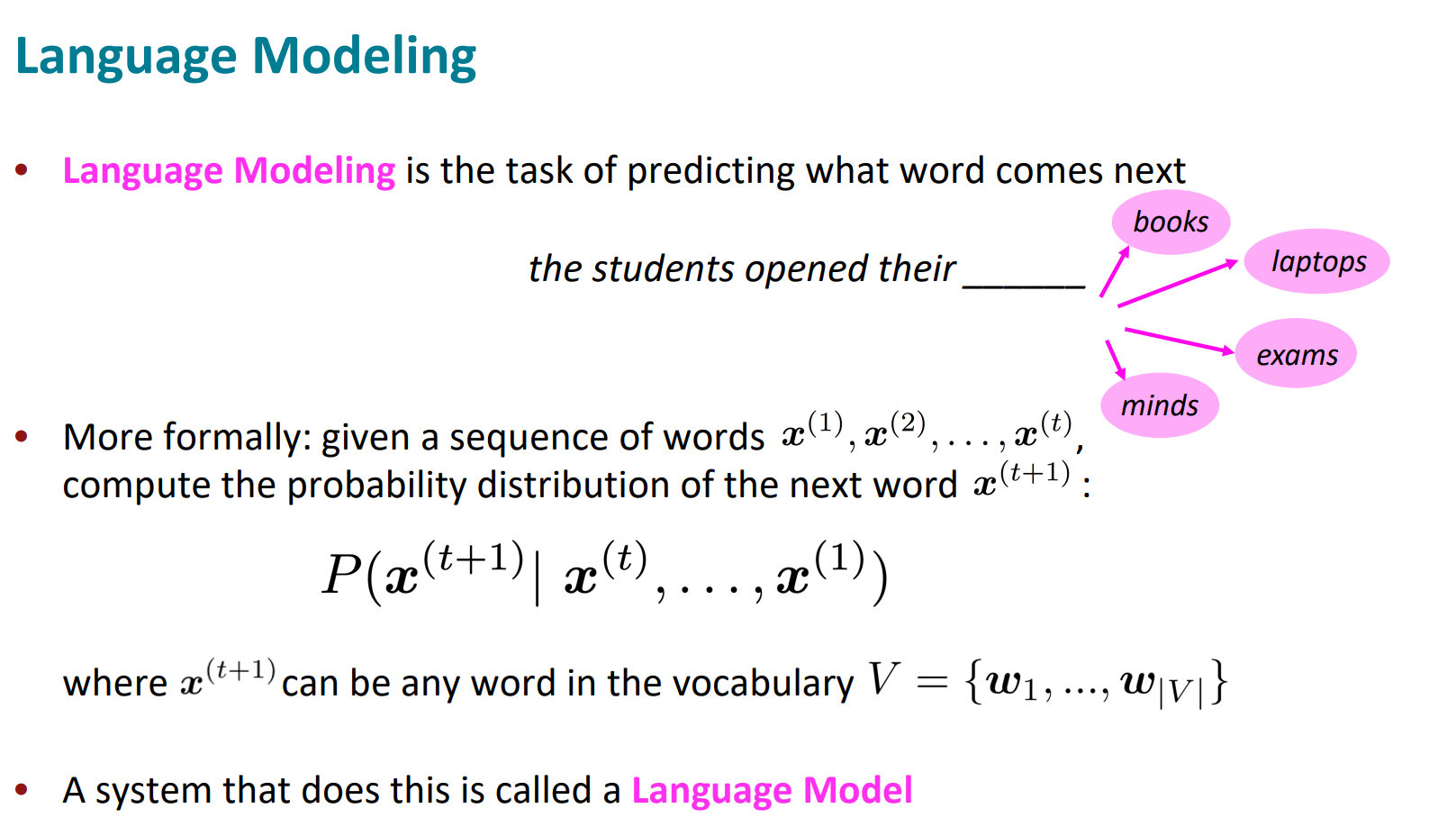
은 이전에 주어진 단어들로 다음에 올 단어를 예측하는거임.

chain rule으로 각 확률을 곱해서 확률을 구할 수 있음

이렇게, 자동완성같은 것도 LM임

NN없는 전통적인 방식은, n-gram이다.
n개의 연속된 단어를 n-gram이라 하고, 얼마나 자주 발생하는지 통계로 LM을 만든다

위치 x(t+1)에 있는 단어가 n-1개의 단어에만 영향을 받는다고 가정하면, 조건부 확률로 나누기로 표현할 수 있고, 그 확률들은 그냥 텍스트에서 count하면서 수집한다.

4-gram이라고 하면, 3개를 가지고 마지막 4번째를 예측한다. n-gram에서 벗어나면 그 context를 반영할 수 없는 단점이 있다.
Naive Bayes는 클래스별 unigram(다른거랑 독립적임)이라는 점에서 n-gram이랑 좀 다름

분자에서 본적 없는 데이터에서는, 확률이 0이 되어버리는 sparsity problem이 있고, 약간의 델타를 추가해서(smoothing) 약간 해결할 수 있다.
분모에서 본적 없는 데이터면, 분모가 0이 되어버린다. 그래서 텍스트 길이를 좀 줄이는(backoff)로 조금 해결할 수 있다.

모든 단어의 순서를 기억해야되니까, 모델이 너무 커져서 저장공간 문제도 좀 있었음

이렇게 확률 분포를 얻을 수 있다.


확률분포를 가지고, 이런 식으로 text generate를 할 수 있다.

이렇게 하면, 문법은 정말 잘 맞는다. 그렇지만 의미는 정말 형편없다.

어떻게 LM을 만들수 있을까? 가장 간단한 방법은 window-based classifier이다.

이렇게 window만 봐서 NN에 넣는 것이다.

이렇게 말이다. 이러면 전체 어휘에 대한 softmax를 가진다.

훌륭한 솔루션은 아니었지만, 가치있었음. 다음에 올 단어를 예측하기 위해 더 큰 context가 필요한 문제를 해결하지는 못했음.
여러 문제점이 있었는데,
- window 크기가 너무 작았다. 더 키울수도 없었다(W가 커지므로)
- 각 단어 x1, x2가 각각 다른 W랑 곱해진다고 봐도 무방하다.(각각 독립적)

그런걸 해결할 수 있는게 RNN임.
hidden state가 있고, 그걸 다시 input으로 공급함(recurrent)
y2를 계산할 때, x2뿐만 아니라 x1의 hidden layer(h1)에 W를 곱해서 공급함.

펼쳐보면, 이렇게 생겼음

장점
- 어떤 길이에도 대응 가능
- t 위치에서 계산할 때, 얼마나 앞에 있던 정보도 활용 가능
- input 커진다고 model이 커지지 않음
- 동일한 가중치를 모든 timestep에 적용돼서, 많이 진행되어도 대치임
단점
- 느림(h1다음에 h2 계산…처럼 행렬연산 아닌 경우가 있어서)
- 실제로는, 많이 뒤에있는 step의 정보를 활용하기 어려움(vanishing gradients)