
이전 단어들을 가지고 다음 단어를 맞추는 모델. 그걸 얼마나 잘하는지 보면서 train할거임. 예측한 단어랑 실제 단어간 cross-entropy가 loss function임.
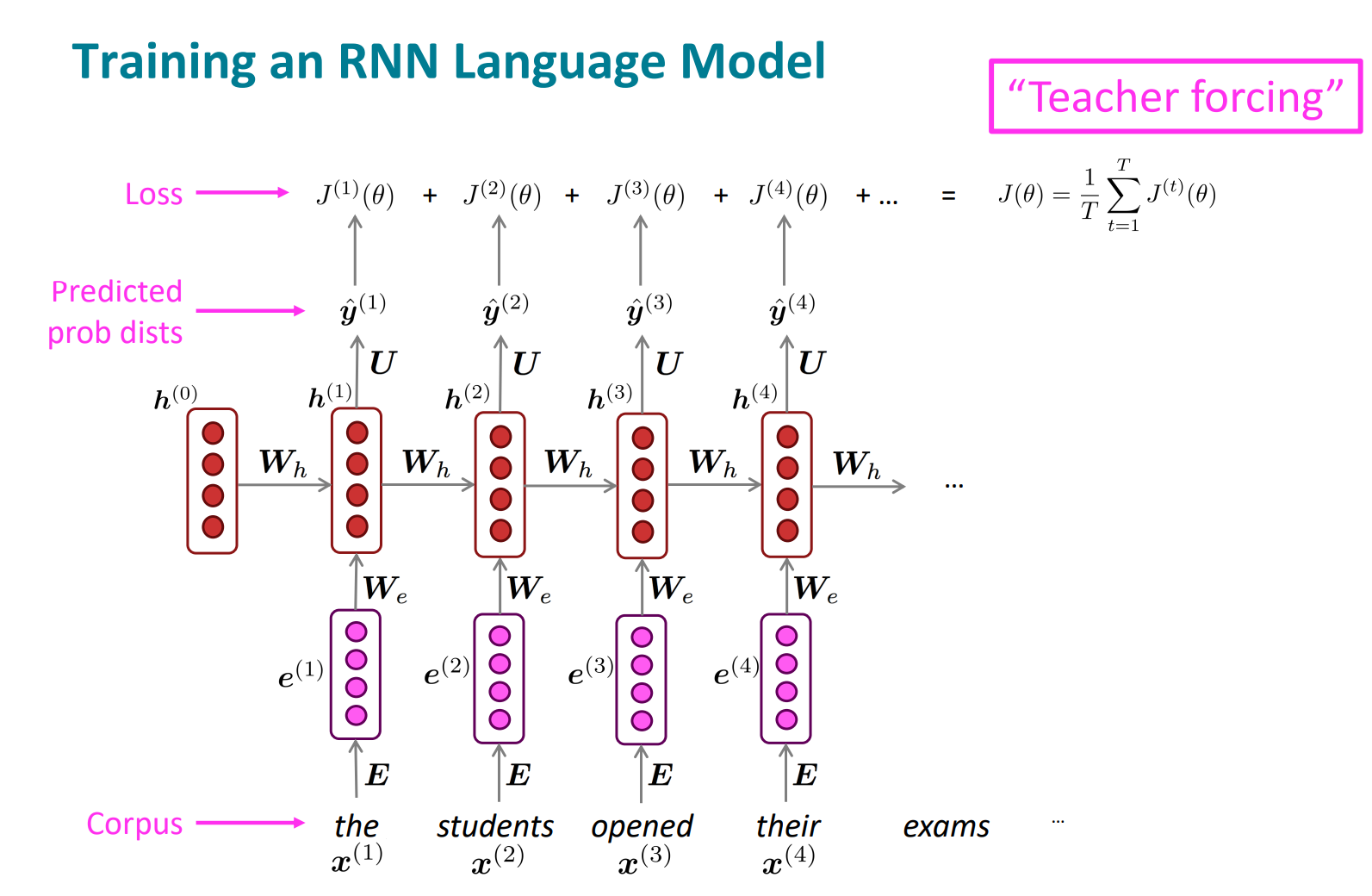
total loss는 각 step에서 loss값을 다 더해서 구함.
teacher forcing처럼, 예측하지 못했을 때 페널티를 주는 방식

한번에 전체 corpus의 loss랑 gradient 계산하는건 너무 비쌈
corpus를 좀 나눠서(문장이나 문서 하나 단위로) SGD사용해서 조금조금씩 구해서 업데이트함

반복되는 weight의 t 시점에서 gradient는 각 시점에서 나타난 gradient의 합임
예를들어, t시점에서 gradient는 1….t시점의 gradient의 합

다변수함수 f(x,y)가 있고 x랑 y가 t에 대한 일변수 함수일 때, 위와 같이 미분할 수 있음

Wh를 모두 같이 사용하기 때문에, 저 분홍색 부분이 1이 되는거임. 똑같이 다변수함수 꼴임 원래는

했던대로 하면, backpropagtation을 그냥 뒤로 쭉 가면서 계산해야함
근데, 한 스텝마다 Wh를 업데이트 하는게 아니라, 맨 끝까지 그냥 저장만 해놓은다음에, 한번에 업데이트해야함.(forward할때 Wh는 불변이었으니까)
긴 문장에 하면 속도가 엄청 느릴 수 있는데, truncated backpropagation trough time(특정 time step만 하고 종료)로 해결할 수도 있음

n-gram처럼 text generating을 할 수 있음.

LM에 대한 평가 방법 표준은
perplexity임. 출현할 단어의 확률의 역수를 정규화한거. 낮을수록 좋음.
쉽게 생각하면, cross-entropy loss인 J(theta)를 exp 한거임.
좀더 쉽게 생각하면, perplexity가 53이면, 53면체 주사위 던져서 1 나올 확률의 불확실성을 갖고있다는 것

언어 모델이 실제로 어떤 일이 있을지는 예상하지 못하기 때문에(그는 XX를 먹었습니다. 했을 때 XX를 예측하진 못하니까) 20정도의 어쩔수 없는 perplexity가 고정으로 있음

LM은 언어를 이해하는거의 benchmark로 사용되기도 하지만, NLP할때 굉장히 중요한 도구가 됨.
어떤 작업이던, 그중 일부로써 LM이 사용됨.

요약하자면
LM : 다음단어 예측
RNN : 모든길이 가능, 각 step에 같은 weight 사용. 그렇지만 LM하고 동치는 아님
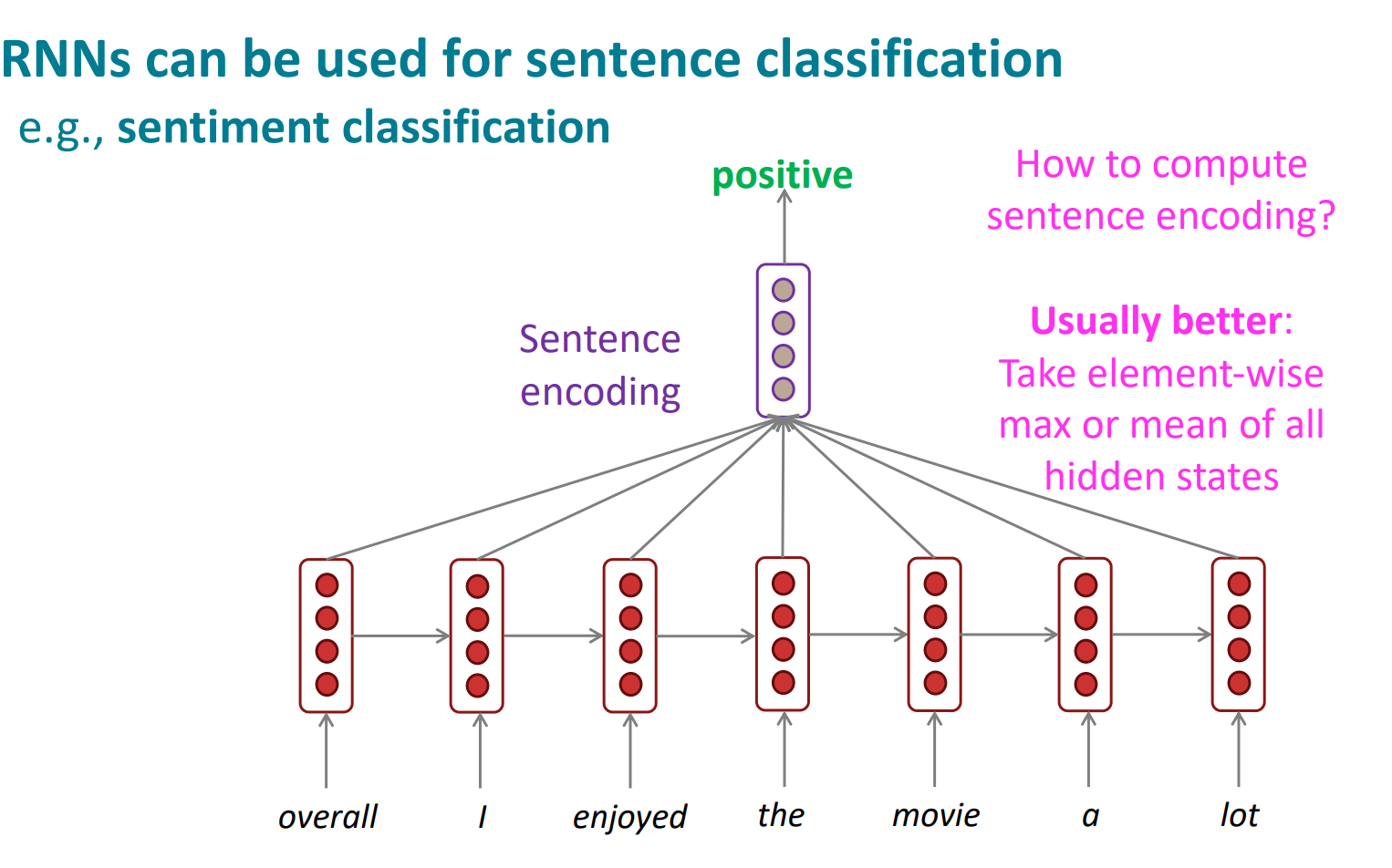
이렇게 품사태깅, 문장 감정 분석 등 다른 task에도 사용가능함
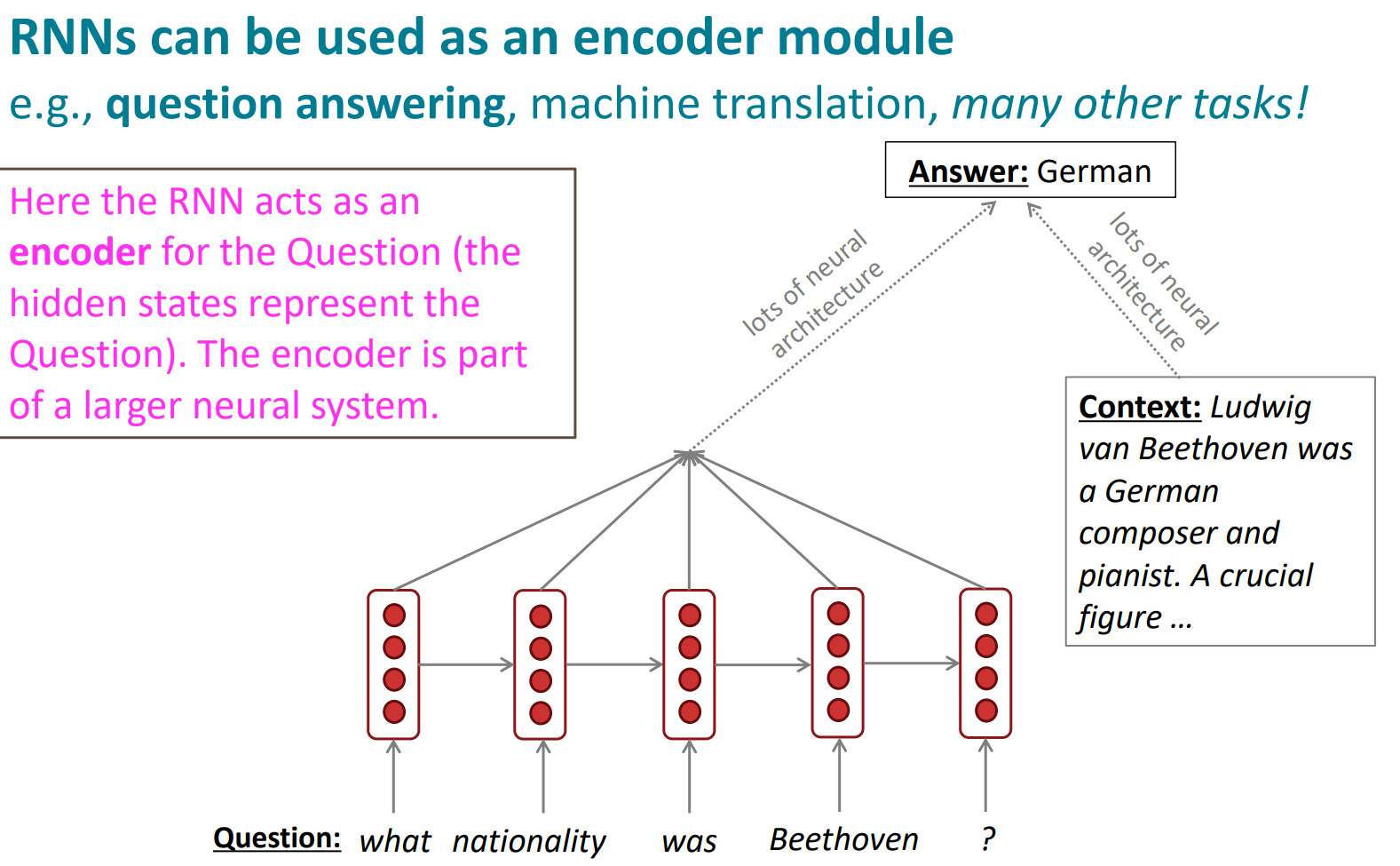
language encoder 모델로도 사용할 수 있음.

이렇게 음성을 받아서 conditional LM처럼 쓸 수도 있음
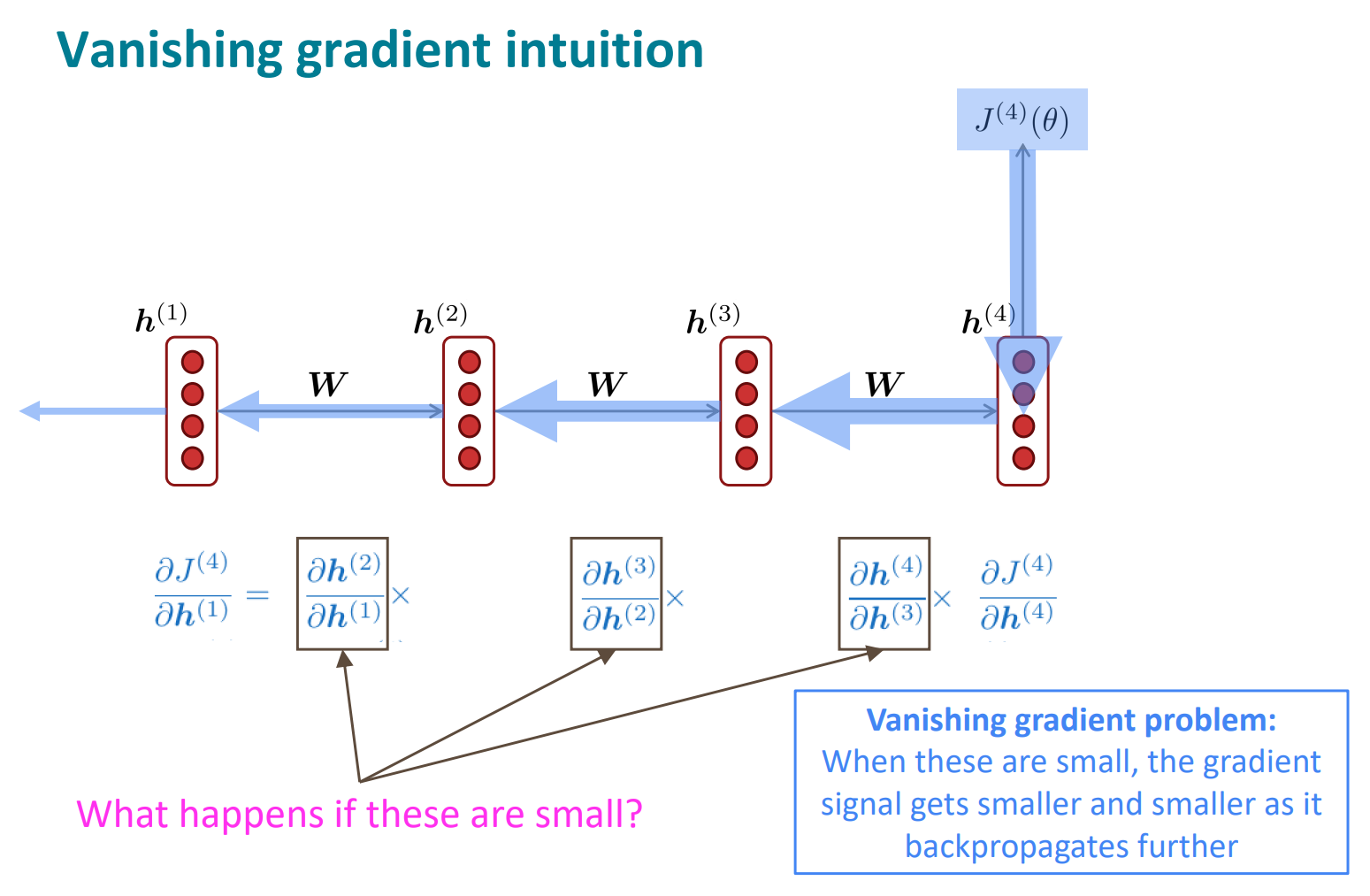
점점 뒤로 갈수록 작아짐. gradient가 점점 작아지고, 사라질정도가 되버리면 parameter를 전혀 변경하지 못함. 이를
Vanishing Gradient라고함

Wh가 작아지면, 제곱을 하니까 기하급수적으로 작아짐(시퀀스 길이가 길어지면)

eigenvalue 값이 1보다 작으면 l이 늘어나면 0으로 0에 가깝게 되버림. 그래서 gradient vanishing이 일어남
non-linear도 비슷하게 똑같은 일이 일어남

h1을 보면 파란 화살표(J4)에서 온거는 미미하게 반영되지만, 노란 화살표(J2)에서 온거는 많이 반영됨. 그래서 주변 효과 모델링엔 좋지만, long-term을 잘 반영하지 못함.

위와 같은 빈칸 문제를 풀 때, RNN은 30개 정도 지나온거라서, 이런 dependency를 배우기 쉽지 않음.

gradient가 너무 커져도 문제가 됨. parameter가 이상해질 수 있음
숫자가 너무 커져서 Inf나 NaN이 나와버릴수도있음

gradient clpping을 통해 이를 막을 수 있음. 주로 20을 쓰는데, 이 것보다 큰 건 취급하지 않겠다는것임

vanishing gradient를 어떻게 막을까?
정보를 더 잘 보존하면 좋을거같은데? → LSTM

1997논문에는 좀 중요한게 빠져있어서(망각) 2000년꺼가 중요함
각 step에 하나의 hidden vector가 아니라, 2개의 vector가 있는 모델.
cell state라는 다른 vector가 있음
cell이 long-term information을 저장할거임. erase/read/write할 수 있음
그리고 gate가 있어서, 각 step에서 gate의 확률을 계산해서 erase/write/read함

이렇게 forget, input, ouput gate가 있고 각 gate를 계산한 뒤, cell state를 계산한다. vector 길이는 모두 n으로 동일하다.
서로 공유하는 parameter가 없어서 병렬로 계산도 가능함

저기 저 + 가 비밀임. 그냥 단순히 더하기 되고있음.
RNN은 그냥 곱셈이었음. 그래서 hidden state의 정보를 장기간 보존하는게 어려웠음.
LSTM은 다음 단계로 정보를 보내는게 쉬움(+니까)

망각=1로 시작하는게 국룰.
그냥 RNN은 Wh가 이전 정보 보관하기 힘듬.
LSTM도 완벽하지는 않음. vanishing/exploding gradient가 나타날 수 있지만, long-term에서 정보가 사라지는것을 막는 쉬운 방법을 제공함

2013~15년동안 LSTM이 NLP에서 가장 강력한 모델이었음.
지금은 Transformer가 가장 강력한 모데임
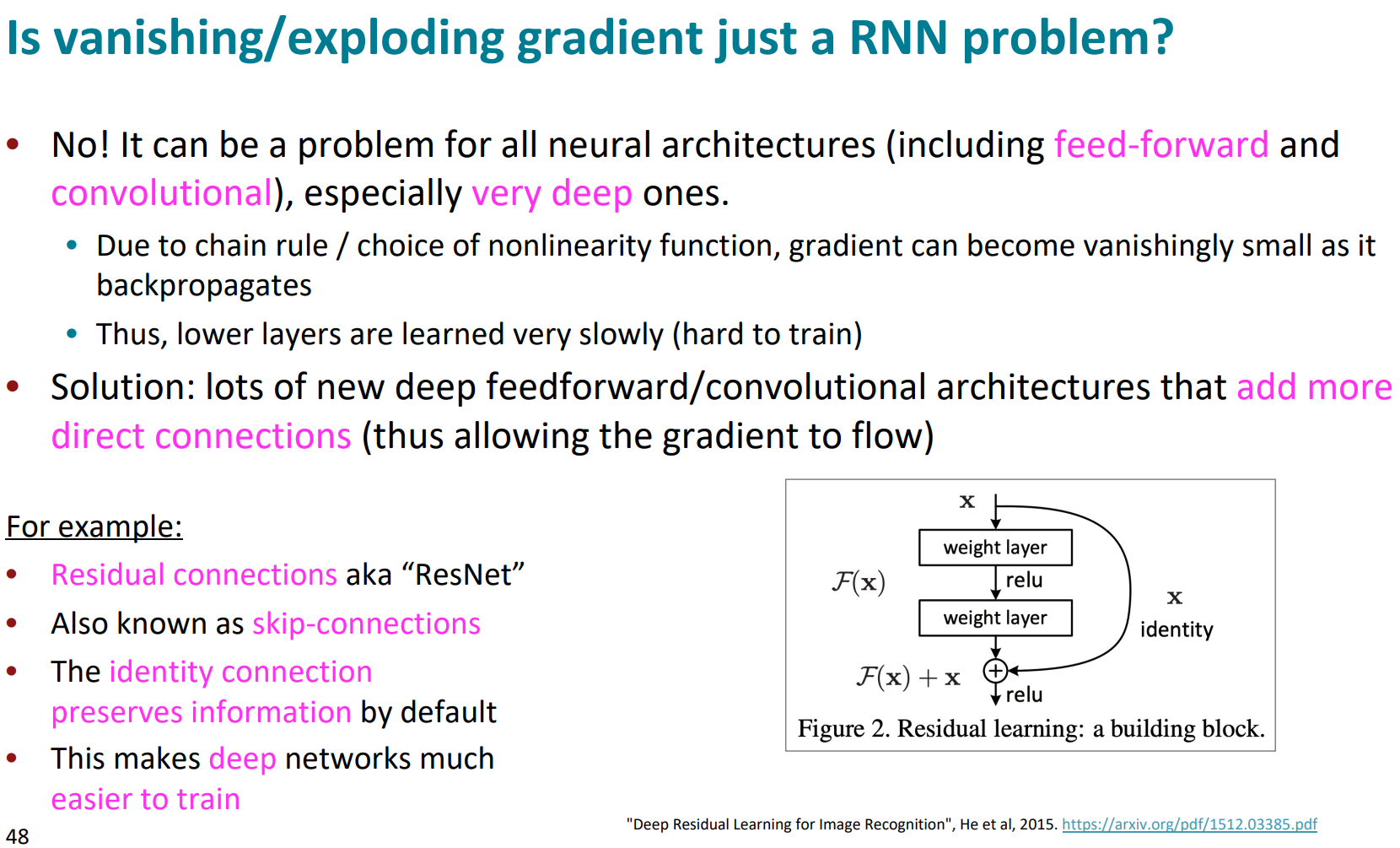
exploding/vanishing gradient는 RNN만의 문제는 아님.
chian rule, non-linearity때문에 모든 deep 모델에서 일어남.
그래서 직접 연결을 좀 해줘서 해결할 수 있음(ResNet 그림처럼)

layer건너뛰는 DenseNet, highway라는 개념을 도입한 HighwayNet등이 이런 문제를 해결하려고 한 노력임


bi-LSTM은 양쪽 LSTM해서 concat해서 구하는거

bi-RNN은 전체 input을 활용 가능할때만 활용가능함
sentiment 분석같은거 할때는 bi가 좋고, LM에서는 그닥…?
BERT가 bidirectional한 transformer임